Designed, developed, deployed, and optimized functional web-servers under a strict budget & explored methods to identify the potential bottlenecks in a cloud-based web service and methods to improved system performance
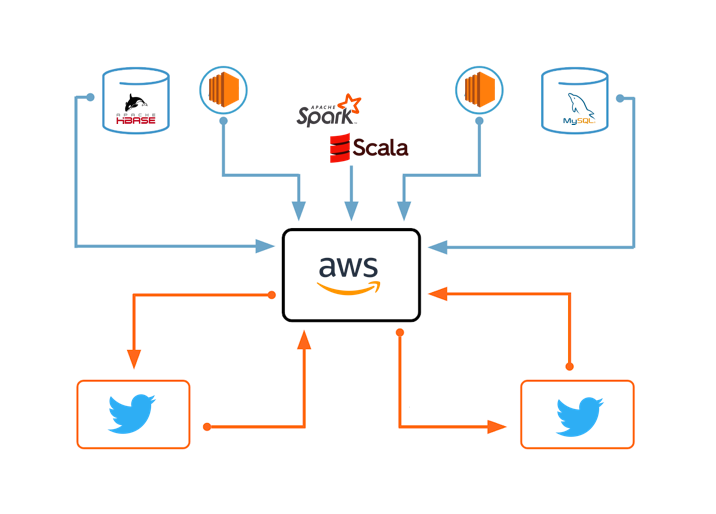
This academic project introduced HTTP Web Servers and how to make them serve 1000s of requests per second;
it also introduced databases (SQL & NoSQL) and the bottlenecks while working with a lot of web server instances and just 1 database instance.
The main goal of this project was to learn how to:
- build a reliable web service on the cloud within a specified budget
- implement ETL on a large data set (~ 1 TB) and load the data into SQL and NoSQL systems
- explore various methods, tools, configurations and optimizations to improve the performance of a web service deployed on cloud managed services


