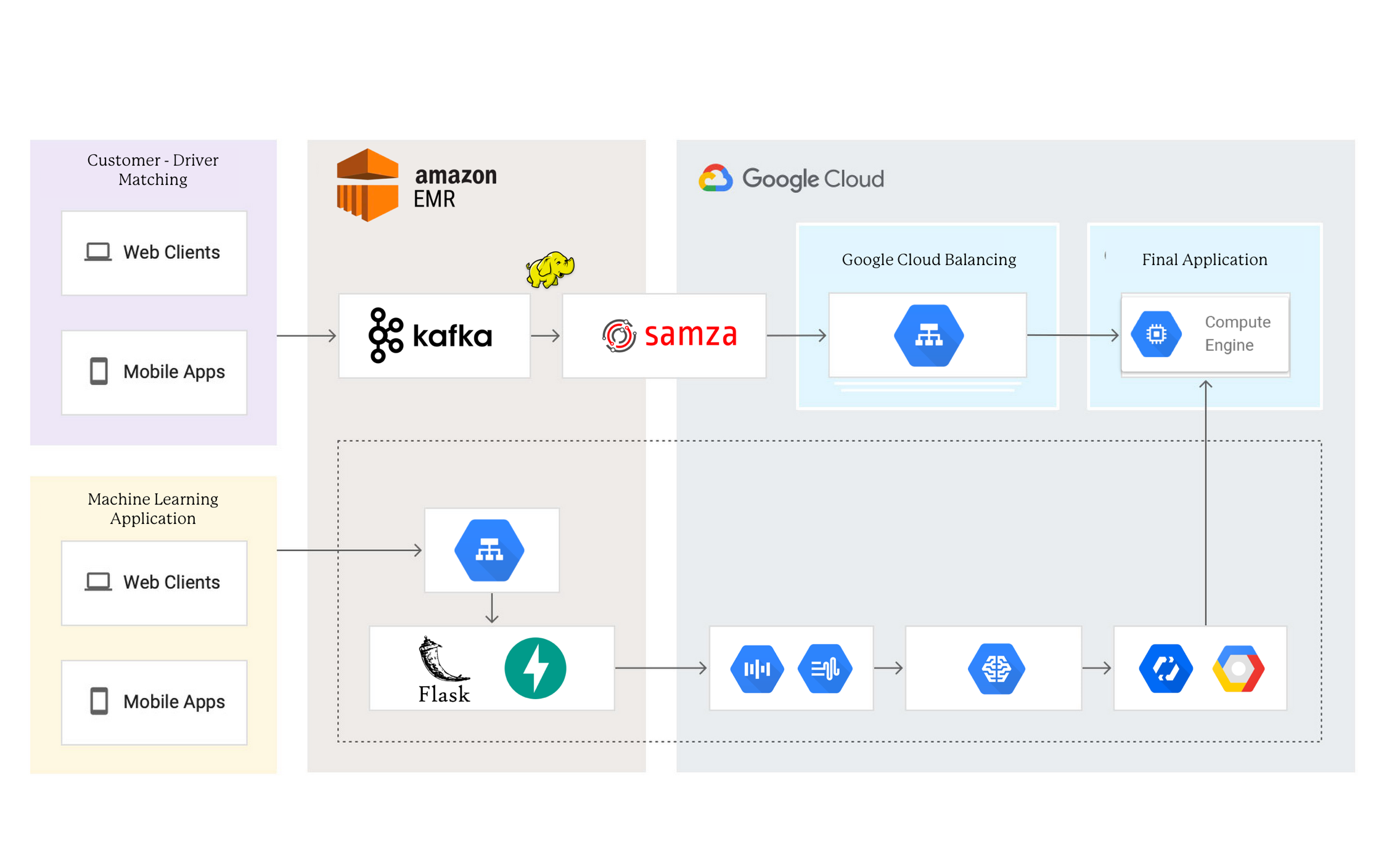
tldr; yes.
I have learned that most of the gains often come from using good features as well as high quality and large data, not from good machine learning algorithms. The quality of the features directly affects the quality of the predictive models. With good engineered features, you can get good results while using a simple model. A bad feature will often have a negative effect regardless of the model sophistication.
Hence, most of the machine learning problems we face become engineering problems rather than algorithm problems.Harshal's Insightful Tip: Use Facets Overview to get some quick insight about the distribution of values across features. You will also uncover several uncommon and common issues such as unexpected feature values, missing feature values, training/serving skew. Set up the Cloud Datalab using
this official guide.You can see the improvement by adding more good features into the model. First, I visualized the data to gain insight; then transferred the insight into code, such as data cleaning or feature improvement; and finally, retrained your model and validate the improvement. Sounds easy! Is not!
data transformation techniques
I cannot discuss the exact approach, but most of my cleaning consisted of: Binarization, Quantization Binning, Log Transformation, One-hot/Dummy encoding, Hashing, and Dimensionality Reduction.
Be very careful about removing outliers from the training set, if you choose to do so. Removing outliers can definitely improve your cross validation score, since you are removing the data points that disagree the most with your model. However, a model trained this way will not generalize well to the test set. Remember, the purpose of your model is to make good predictions on data that are unseen in training.
hyperparameter tuning
tldr;
Follow this official guide by Google.With
Google ML Engine, I did not host/configure your own virtual machine, manage the dependencies required for machine learning, or write code from scratch to orchestrate multiple workers and distribute the workload to achieve parallel training. This greatly simplified the process of scaling machine learning to elastic resources on the cloud -- simply upload the code that trains the model and ML Engine will take care of the rest. it supported scikit-learn, XGBoost, Keras and TensorFlow.
Hyperparameters, cannot be learnt during training directly but are set before the learning process begins. Hyperparameters affect the training thus the model performance, and therefore there exists a need to tune hyperparameters to improve the accuracy of the models. For example, you could train your model, measure its accuracy (e.g., RMSE in my case), and adjust the hyperparameters until you find a combination that yields good accuracy. The scikit-learn framework provides a systematic way of exhaustively searching all the combinations of the hyperparameters with an approach known as Grid Search. While hyperparameter tuning can help to improve your model, it comes at the cost of additional computation, since you have to re-train the model for each combination of hyperparameters.